Welcome to Blackfish
Blackfish is an open source "ML-as-a-Service" (MLaaS) platform that helps researchers use state-of-the-art, open source artificial intelligence and machine learning models. With Blackfish, researchers can spin up their own version of popular public cloud services (e.g., ChatGPT, Amazon Transcribe, etc.) using high-performance computing (HPC) resources already available on campus.
The primary goal of Blackfish is to facilitate transparent and reproducible research based on open source machine learning and artificial intelligence. We do this by providing mechanisms to run user-specified models with user-defined configurations. For academic research, open source models present several advantages over closed source models. First, whereas large-scale projects using public cloud services might cost $10K to $100K for similar quality results, open source models running on HPC resources are free to researchers. Second, with open source models you know exactly what model you are using and you can easily provide a copy of that model to other researchers. Closed source models can and do change without notice. Third, using open-source models allows complete transparency into how your data is being used.
Why should you use Blackfish?
1. It's easy! 🌈
Researchers should focus on research, not tooling. We try to meet researchers where they're at by providing multiple ways to work with Blackfish, including a CLI and browser-based UI.
Don't want to install Python packages? Ask your HPC admins to add Blackfish to your Open OnDemand portal!
2. It's transparent 🧐
You decide what model to run (down to the Git commit) and how you want it configured. There are no unexpected (or undetected) changes in performance because the model is always the same. All services are private, so you know exactly how your data is being handled.
3. It's free! 💸
You have an HPC cluster. We have software to run on it.
Requirements
Python
Blackfish requires Python to run locally. Alternatively, Blackfish can be added to your university's Open OnDemand portal, which allows users to run applications on HPC resources through a web browser. For more information, see our companion repo blackfish-ondemand.
Docker & Apptainer
Blackfish uses Docker or Apptainer to run service containers locally. Services run on HPC clusters rely on Apptainer.
Quickstart
Step 1 - Install blackfish
Step 2 - Create a profile
blackfish init
# Example responses
# > name: default
# > type: slurm
# > host: della.princeton.edu
# > user: shamu
# > home: /home/shamu/.blackfish
# > cache: /scratch/gpfs/shared/.blackfish
Step 3 - Start the API
Step 4 - Obtain a model
Step 5 - Run a service
Step 6 - Submit a request
# First, check the service status...
blackfish ls
# Once the service is healthy...
curl -X POST 'http://localhost:8080/transcribe' -H 'Content-Type: application/json' -d '{"audio_path": "/data/audio/NY045.mp3", "response_format": "json"}'
Details
Blackfish consists of three primary components: a core API ("Blackfish API"), a command-line interface ("Blackfish CLI") and a browser-based user interface ("Blackfish UI"). The Blackfish API performs all key operations while the Blackfish CLI and UI provide convenient methods for interacting with the Blackfish API. Essentially, the Blackfish API automates the process of hosting AI models as APIs. Users instruct the Blackfish API—directly or via an interface—to deploy a model and the Blackfish API creates a "service API" running that model. The researcher that starts a service "owns" that service: she has exclusive access to its use and the resources (e.g., CPU and GPU memory) required to deploy it. Blackfish tracks the status of users' services and provides methods to stop services when they are no longer needed.
In general, service APIs do not run on the same machine as the Blackfish application. Thus, when a researcher requests a model, she must specify a host for the service. The service API runs on the specifieid host and Blackfish ensures that the interface is able to communicate with the remote service API. There are several ways for researchers to setup and use Blackfish depending on their requirements. For testing and development purposes, users can run everything on their laptop, but his option is only practical for models with light resource requirements. Typically, users will want to run services on high-performance GPUs available on an HPC cluster with a Slurm job scheduler. In that case, researchers can run the Blackfish API on their local laptop or on the HPC cluster.
Note
Blackfish doesn't synchronize application data across machines. Services started by an instance of Blackfish running on your laptop will not show up on an HPC cluster. However, job data for services initiated by your laptop will be stored on the remote cluster.
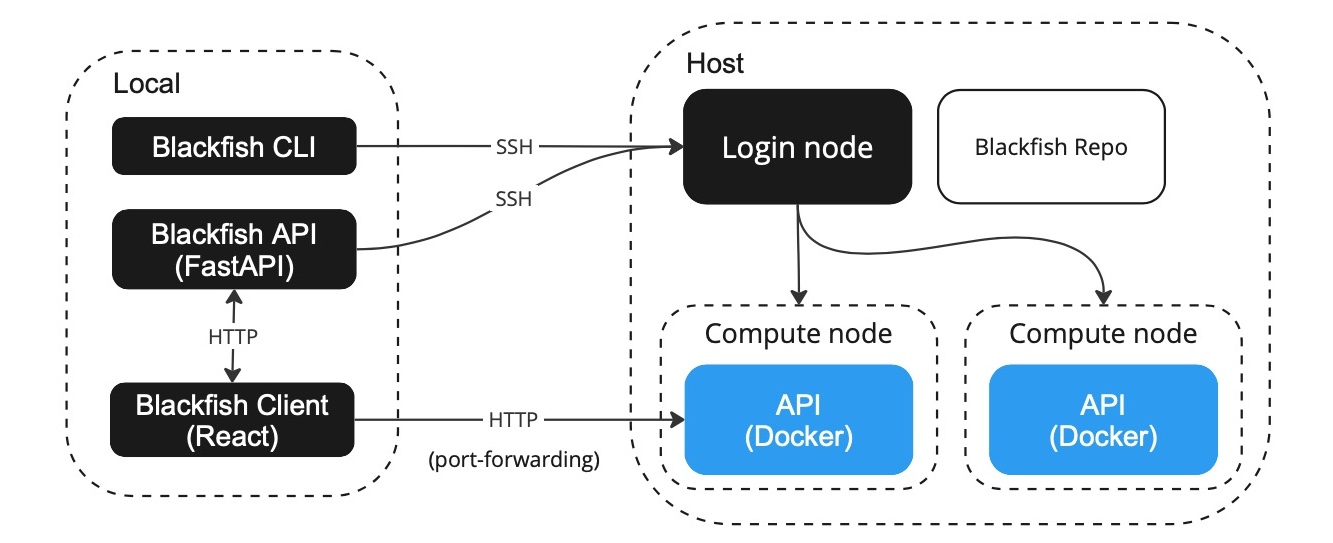
Figure The Blackfish architecture for running remote service APIs on a Slurm cluster.
Acknowledgements
Blackfish is maintained by research software engineers at Princeton University's Data Driven Social Science Initiative.
-
Support is currently limited to clusters running the Slurm job manager. ↩
-
Inference results may not be "exactly reproducible"—i.e., generating same outputs from same inputs—depending on the details of the model and inference settings. Blackfish allows researchers to "reproduce" findings in the sense of running the exact same model with the exact same settings. ↩